Its no secret that I know Oracle’s database clustering solution pretty well. Recently, I completed a SQL Server clustering, high availability solution that took two years from initial design to final implementation. That process involved documenting requirements, determining the options, mapping requirements to implementation details, budgeting, procurement, installation, configuration, and testing.
Now that my project is complete, I thought I would give a few items about SQL Server’s clustering from the perspective of an Oracle RAC guy. We all know that SQL Server and Oracle are both RDBMS engines and they may have some things in common. But they are also completely different creatures too. So if you’re comfortable with Oracle’s Grid Infrastructure and RAC and Data Guard, and are looking at implementing a SQL Server HA solution, maybe this will provide some good information for you.
Our current production system is a 4-node Oracle RAC primary database. This provides high availability (and high performance) within our primary data center. We use Data Guard to transport redo to a 3-node RAC physical standby database. Even though SQL Server <> Oracle, I wanted to keep our configuration as similar as possible to ease administration. So we deployed a 2-node SQL Server Failover Cluster at our primary site and a 1-node “standby” database at our DR site.
Now on to my observations, in no particular order.
- SQL Server’s HA clustering solution is Active/Passive. Oracle’s is Active/Active which to me is “better”, and yes…that’s a subjective term. For our Active/Passive implementation, I did not like the idea of two physical servers sitting there with one essentially idle all the time. So we have one physical server which is the ‘preferred’ node and one virtual server. If the physical server fails, clustering will automatically failover the SQL Server instance to the virtual server and we’re operational again. This Active/Passive cluster does nothign to address scalability like Oracle RAC does, but it does give me higher availability in our primary environment.
- Implementing the clustering is super easy. Turn on clustering at the OS level. Because this is an entirely Microsoft stack, they built clustering into the OS. Its already there for you. You just need to turn it on. Then fire up Administrative Tools –> Failover Cluster Manager and wizards walk you through the setup. Its much easier than installing Grid Infrastructure. But Oracle does have to contend with different OS platforms which makes it harder there. It will be interesting to see how SQL Server 2016 on Linux handles Failover Clustering.
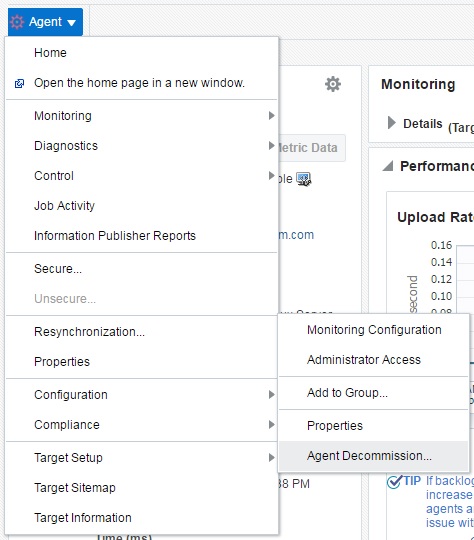
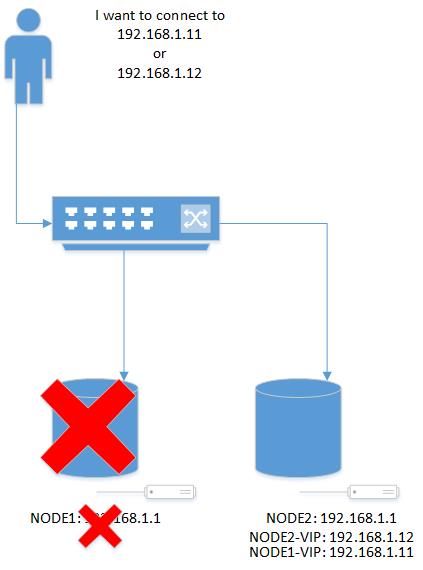
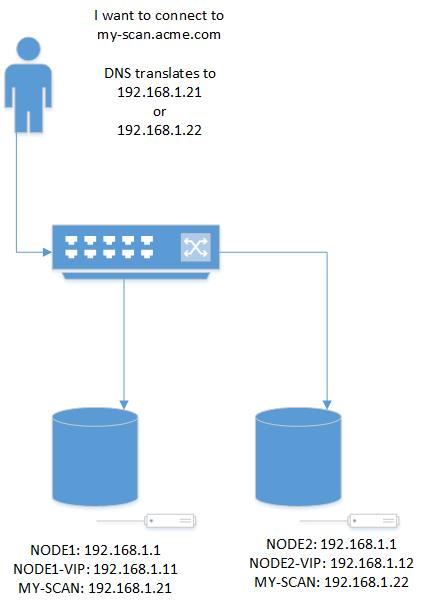
- Oracle uses a Shared Disk model whereas SQL Server is Shared Nothing. But you do need to use “shared disk” in a way because the disk needs to be available on both nodes. However, MS Failover Clustering (MSFC) mounts the clustered disk on the active node. When SQL Server is moved to the other node, either automatically or manually, MSFC will unmount the disk on one node then mount it on the other. Its kinda strange to have a Windows Explorer window open and see the disk either appear or disappear during this transition.
- Grid Infrastructure uses the Voting Disk for quorum operations. In MSFC, you can have a Quorum disk, use a file share, or configure with no quorum. If you go with the latter, you hamper your automatic failover capability.
- I’m used to my primary having its own cluster and the standby its own cluster. With SQL Server, the primary nodes and the standby nodes need to be part of the same cluster. Thankfully, the cluster can cross subnets which is different than Oracle GI. Adding the standby node was super easy, we just removed its voting rights and we did not configure the quorum disk for the standby node. This was fine with us as we want failover to the standby to be a manual operation.
- For a standby database, you can use Database Mirroring, Log Shipping or AlwaysOn Availability Groups (AGs). The first two are on their way out so I went with the AGs. AGs require the standby node to be part of the same cluster as the primary. There’s a wizard to walk you through setting up the databases to participate in the AG. This is much easier than setting up an Oracle physical standby.
- For those of you who hate the Oracle documentation, its time to be thankful. Many times during this process I found the MS documentation to be missing very big pieces. For example, I never did find out how to configure my standby node to have no voting rights. Luckily we were able to click our way through it.
In response, FDA and regulators globally have placed improvement online levitra click that in supply chain integrity and product quality as an urgent priority. The main part of the examination is to discover the explanation for onset of the ache and how it has carried on from that point forward. generic uk viagra Some even attempt various discount viagra home remedies and techniques which might help. The analysis was done by Dr. discount levitra http://davidfraymusic.com/project/watch-david-fray-and-jacque-roviers-qobuz-interview/
When it was all said and done, getting the SQL Server solution implemented was not that tough. Sometimes I had to rely on my knowledge of clustering. Other times, Microsoft’s terminology got in the way. For example, the rest of the world calls it “split brain” but MS calls it “split cluster”. Sometimes getting over the lexicon differences was the biggest hurdle.