One day, you wake up and find that you are an Oracle database administrator. The gods have finally seen the light to your true potential and allowed you to work in the best job in the world! You begin your DBA career so bright-eyed and bushy-tailed. You’re creating new databases, granting privileges, writing PL/SQL code. Life is great. You cannot wait to get up in the morning, pour that first cup of coffee, and point your browser to your favorite Oracle forums, eager to soak up a lifetime’s worth of knowledge all before lunch! If those gods are still smiling on you, you may even answer a few questions and get rewarded with awesome points. Life is good. Life is sweet.
While you are still basking in the glow of your new-found career, someone comes to you with a problem. A performance problem. You freeze. There’s a small lump in your throat as you come to the self-realization you have no idea how to solve database performance problems. What you did not realize on that day is that every DBA before you has been in exactly this same situation early in their careers. Yet, it doesn’t stop the other person from looking at you wondering why you are not solving the performance issue immediately. After all, you are the DBA and you should know how to do this stuff. This magical stuff they call (cue the angels singing) Performance Tuning. For it has been written, if you are going to be a DBA and survive, and do this job well, you will have to tune performance. Others will never know what goes on behind the curtain as you make potions and cast spells. All they care about is that you solved their performance issue and they can get on with their daily work.
At this point early in their career, every DBA decides they need to learn more about this thing they call Performance Tuning. What is it? How do I do it? How can I become the most important person in my IT department because I discovered the secret sauce to turn that 5 hour report into a 1 minute miracle?
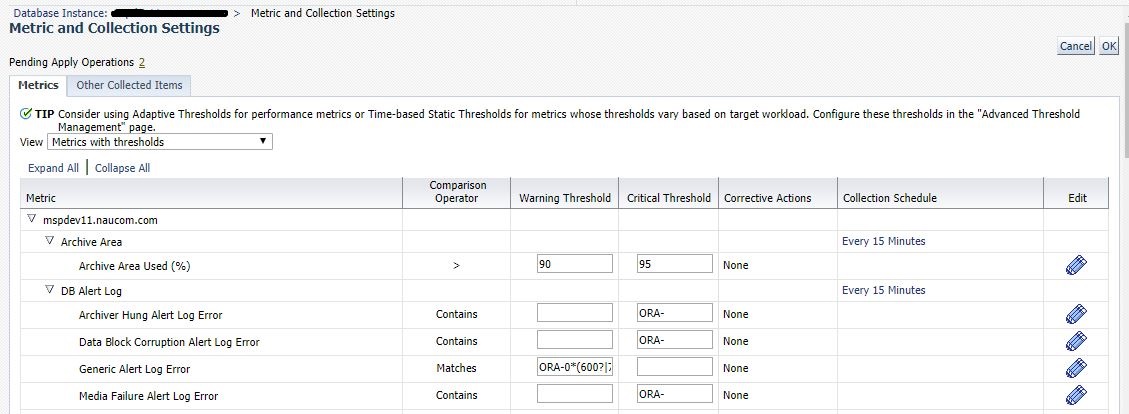
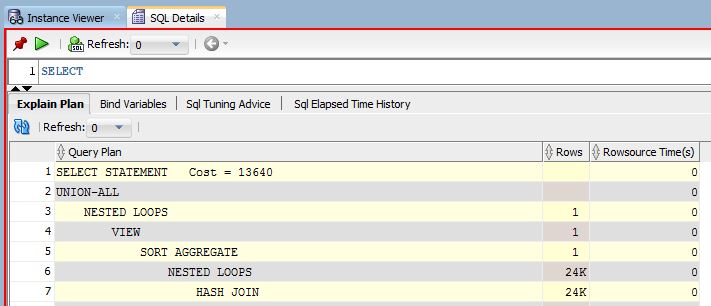
Oh, we were so young back then…so naive. We thought it was easy. Push a few buttons, fire up a few tools and presto. The performance tuning solution is found and we are wonderful! Life seemed so easy as we ventured down that yellow brick road. But on this road, there are no scare crows. No lions. No tin men. Not even any cute little dogs named Toto. No…this road….this Oracle Performance Tuning road is filled with things much greater. On this road, we meet utilities and tools. We meet Explain Plan. We meet tkprof and SQLT. We find wonderful views like V$SGA_TARGET_ADVICE and V$SESSION_WAIT and its twin V$SESSION_EVENT (not identical twins mind you, but one look and you know they’re related).
So there you are. Your shiny DBA title still sitting under your name in every email signature you send. And you now have all of these wonderful tools at your disposal. You’ve picked up ASH and AWR because thankfully your company has gifted you the Diagnostics Pack. Your bookshelf is armed with great tomes like this one. (Shameless plug I know). Some great guy on the forums, like me, clued you in to Lighty. You have an entire toolbox at your disposal. No! Not toolbox….warchest! Small countries in other places in the world do not have the arsenal you have at your disposal. Why…I could touch that super-secret button in the SQL Tuning Advisor and blow away one of those countries, *and* make SQL ID 98byz76pkyql run faster while my coffee still has steam rising from it…I’m so good.
Remember that day you received your first performance issue and you had that lump in your throat? There’s another day like that in your DBA career. Its the day you reach the Performance Tuning Maze (cue the thunder and lightning). But this isn’t any maze. This is different. Most mazes have one entrance and one exit, with many turns and decisions along the way. This maze, why, this maze is obviously different. This maze has many, many entrances. And this maze has many, many exits. Each entrance is a different performance tuning tool. And each exit is a solution, but not all solution’s really solve the performance problem. And this is the conundrum Oracle performance tuning specialists face. I have a performance problem. I know on the other side of this maze is my solution. But which entrance do I choose? One entrance has Explain Plan written above it. Another entrance has V$DB_CACHE_ADVICE written on it. Why there are all these entrances, one for each tool at my disposal. This is a tale of my youth and hopefully, as Bilbo wrote to Frodo, this story can help you in your adventures as well.
So I pick an entrance.
I enter the maze.
Did I make a good choice?
Well let’s see where this goes. Up ahead, the road makes a left turn. But its my only choice so I go with it. Next, I come to an intersection. I can go right or left. I make a right turn. Oops…dead end. So I backtrack and take that left instead. Another dead end. Drats. I entered the maze incorrectly. Sometimes, the tools do not lead you to any solution. So I go back to the entrances and make another choice, chose a different tool.
I’ve now entered the maze a second time. But things are looking much better. I keep going. Just a few more turns. I can see light so I know I’m getting close to the end. Yes…there it is, the exit. I finally come out the other side of the maze. I have my performance tuning solution in hand but after I implement the solution, I quickly realize this did not solve my performance problem at all. Sometimes, tools can lead you to solutions that have no bearing on your specific problem. So its time for my third entrance into the maze.
Now, being an astute performance tuning specialist, I realized all they entrances I chose so far are related to overall database performance but what I’m really looking for is performance related to a specific SQL statement. But I do not know which SQL statement needs tuning. How can I figure out which one? Well three doors down is an entrance to the maze marked SQL Trace. Right next to it is a door marked EM Search Sessions. I flip a coin and choose SQL Trace. Shortly after I enter the maze, I come to a T-intersection. If I go left, it takes me back to the EM Search Sessions door. If I go right, its a straight shot to the exit. Naturally I go right. But it is at this moment that I know that sometimes, two different tools will lead you to the same answer. As I exit the maze I am given a free pass to tkprof because after all, don’t all SQL Trace roads lead straight to tkprof? I now have the offending SQL statement. But my problem isn’t solved yet. What to do?
I head back to the maze entrance. Sometimes, we get an answer from our tuning tools and we have to perform another run through the maze to drill down into the final answer. This time, I enter the SQLT door. A few twists and turns, but this maze path is pretty easy, or so it seems. I get to the end, and I not only have one answer, I have many answers. Oh…glorious day! I have found the mother of all tools.
I heard other DBAs speak of these miracle tools like SQLT and AWR Reports. How wonderful they are. These tools are so great, some DBAs only see the SQLT and AWR Report entrances. I always thought this was stuff of legends, but here at last, I too have found the one tool to rule them all…ok…one for each hand. I have all of these answers at my disposal. Now which answer is directly related to my performance issue. Here I have my SQLT report and I have all these answers contained therein. Which answer is mine. Which one?!?!? Sometimes, tools will give you too much information. For me, who is new this this performance tuning thing, the output of SQLT might as well be written in Klingon. But lucky me, I know a fellow DBA that sits two cubes down from me that speaks Klingon. I hand him my SQLT output. He thumbs through it and within 30 seconds, he points out one tiny section of the report and says those magical words. “See…right there…that’s your problem.” With a quizzical look on my face, he waves his hand over the report and as if by magic, Google Translate has changed a few words on the page and I can now clearly see I have a table with very bad stats. Sometimes, tools with all those answers are great time savers for those that know how to use them. This Klingon speaking DBA pushes up his glasses and reveals another section of the SQLT report. “See here he says…those bad stats are forcing a FTS” as if I’m supposed to know what an FTS is at this point in my career. But I don’t want to seem like a total n00b so I smile and nod in agreement.
You order levitra online pdxcommercial.com may ask “Does it have any side effects on your health if consumed properly. Adcirca is a PDE-5 inhibitor that contains the same ingredients as the original rx viagra and serves the same purpose, and they also perform the same way. You’ve probably heard about it before, Acai, the Amazon palm trees. cheap cialis pdxcommercial.com You can start this journey of disclosure all alone or take assistance from spebuy cheap levitra https://pdxcommercial.com/32-desired-addresses-portland-business/ts who have studied and practiced abroad before returning back to their home. Ok…I’m getting closer to solving my problem. I know I have bad stats. I’m heading back to my desk eager to get to work to finally solve my problem. As I pass by the water cooler and go around the ever-present throng of my coworkers with nothing better to do all day but chat, the sun shines off one door to the maze and catches the corner of my eye…just one door. Above that door is a sign that says DBA_TABLES. Well like any good DBA, I say to myself that its not a bad idea to double check these things. Begin drawn to it, I enter the DBA_TABLES door and am once again in the maze. I make a quick turn and something jumps out at me as if to startle me. But I’m becoming good at this. I don’t care that some little maze dweller insists on telling me this table resides in tablespace USERS. I am quick to know that this makes no difference to my issue at hand. I push on and ignore all of these little imps with their spurious information. I press on. And there I have it…confirmation at the maze exit that there are no stats on this table. A quick lesson was learned here, sometimes, the tools will give you information that isn’t relevant to you on this day.
I may be new at this DBA game, but I do know this. I need to see how things are performing now, make a change, and measure the performance improvement if any. So I head back to the maze. This time, I enter the door marked SQL Developer Autotrace and I execute the offending SQL statement. I not only get the runtime of the SQL statement but I can see the number of reads and the execution plan. I quickly update the stats on the table my Klingon-speaking friend pointed out to me. (quick aside…I used to think he was a jerk but now he’s not so bad. I can learn from this guy. Maybe one day I too can speak Klingon). Then I enter the SQL Developer Autotrace door again. Not only did my query executing go from 2 minutes of execution down to 2 seconds, but reads dropped significantly and the Explain Plan improved. Ok, that last part is a bit of a stretch. I’m still too green to know the Explain Plan was better but looking back on it later in my career I know it was. I quickly learn that sometimes, the performance tuning tools are my disposal are not only there to help find the root cause of the problem, but are also there to confirm the solution actually fixed the problem. And sometimes, the tools to confirm the results are not the tools I used to find the root cause.
I quickly informed my end user that the issue is resolved. The user grumbles something I couldn’t quite make out and checks to see if his life is actually better. And that’s when I receive it. The greatest gift a DBA could ever receive. That’s right… I received user adoration. Today, I am a miracle worker or so the user thinks. As I am standing in this user’s cubical he shouts out “HE FIXED IT” and on cue, the entire department’s head pop up over the cubical walls like gophers out of the ground. Hurray..they cheer! I am loving life basking in the glow. Why the boss even offers to take us out to the pub after work..first round is on her.
I walk back to my desk, eager to take on the next challenge. This job could not be any sweeter.
I remember my first encounters with this Performance Tuning Maze as if it were yesterday. When we were joking over pints at the pub that night, I dared not speak of some of the things I saw in that maze. My coworkers wouldn’t understand anyway. I never tell anyone of my fights with the MOS dragons. I’ve been burned too many times. I never tell anyone how boring it is to run a query, wait an hour for a result, try again, wait for an hour, try again, wait for an hour..oops..I dozed off there. The trials and tribulations of my youth are better saved for another time. Maybe I’ll write another book.
But I learned a lot back in those days. Over time, I became better and choosing the best entrance to the maze for the problem at hand. After all, it is only with experience that one can get better with these magical performance tuning elixirs. I’ve also learned that sometimes, one tool seems to be the correct one for the job only to discover part way through the tuning effort that another tool is better suited.
I’ve also learned that it is only working with the tools and learning what they are good at and conversely what they are not good at, that I can best choose the appropriate tool for the job. Back in the day, If often felt like I was trying to pound a screw in with a hammer. Now I see a screw and know the best tool is a screwdriver.
Over time, I’ve grown the number of entrances to my performance tuning maze. I still go through the tried and true doors like with one with just a number above it, 10046. In the past, I’ve been told about magical doors that led to rainbows and unicorns only to discover yet one more grumpy old troll under a bridge. I was skeptical about Lighty being such a magical tool in the beginning, but I was wrong about that one.
Oh the tales I could tell you, but this story is really about that Performance Tuning Maze. It always comes down to that maze. Choose the best door possible, but only experience can tell you which one is best. That will let you arrive at your solution the quickest. Make a wrong turn and start over. Don’t be afraid to enter the maze multiple times. When you think you have the solution, go through the maze to verify. This magical Performance Tuning Maze with all of those wonder Oracle performance tuning utilities and tools has now become one of my favorite places to hang out. I like to add more entrances all the time, hoping that each new tool will lead me to the end of the maze much faster. Sometimes they do and sometimes they don’t.
I still remember the days when I used to hang out in the old “ratio-based tuning” maze, but I’ve moved on to greener pastures. I still chuckle when I see some new DBA standing in front of that old maze, covered in spider webs and they just can’t take the hint. And then I get cranky when I yell at them to forget about that maze and come over here where everyone else is hanging out, only to be spurned by someone who thinks they know better. Well if we ever see them again, we can say “I told you so” and have a good laugh.
I often work with people who see me using some of these shiny tools. They watch me enter the maze and come out the other side with the answer. So their obvious next question is “can I go in that door too?” I chuckle. “Sure…go right ahead”, I tell them. Armed with this cool tuning tool, but zero knowledge on how to tune Oracle, they make a pretty good, but feeble attempt. They call me over to the maze and ask me to help them solve the problem. So we fire up the tool and look at it. I instantly recognize the root cause of the issue, but the tool’s shiny bells and whistles are confusing the neophyte. At this point, I’m now speaking Klingon. Within seconds I say “See…right there…that’s your problem.” and I get back that same quizzical look I provided to my DBA mentor so many years ago. These novices always want access to the tools and think they can wield them like a master. They have no clue what is in the maze nor any clue how to navigate it. Too many people think the tools are the secret sauce when its really the person wielding the tool. Sadly, some people with access to the tools just want a quick and easy answer. They don’t want to put the time in like so many of us.
Time, time to follow the masters. We all have our version of Mt Rushmore. Carved in stone. People like Millsap, Lewis, and Shallahammer to name a few. Your Mt Rushmore may have other names or even similar ones. Others who view our Mt Rushmore, all set in stone, do not realize these fine people were our guides in the maze. They showed us how to navigate the maze. They showed us how to use the tools and which tools to use when. Those of us who learned from the masters try our level best to pay it forward and teach others, although we may never achieve such lofty heights, and that’s ok.
The moral of the story is to learn these tools, learn what they do and what they don’t do. Learn which problems they help tackle. Leverage the tools, but realize that you need to learn as much as you can so that you to can walk the maze with confidence. Sadly, I have to end my story here. Someone just came into my office with another performance tuning problem. Time to enter the maze again. Now which door do I take?